CFPS小课堂 | 如何对形形色色的方言进行编码 · 用户手册篇(九)
来源:时间:2022-05-13 11:34阅读:
CFPS基线和后续追踪调查问卷分别通过受访者自答以及访员观察采集了受访者平时交谈使用的语言,以及访问过程使用的语言。
下表为2010、2012、2014年问卷中有关方言的问题及相关变量名。
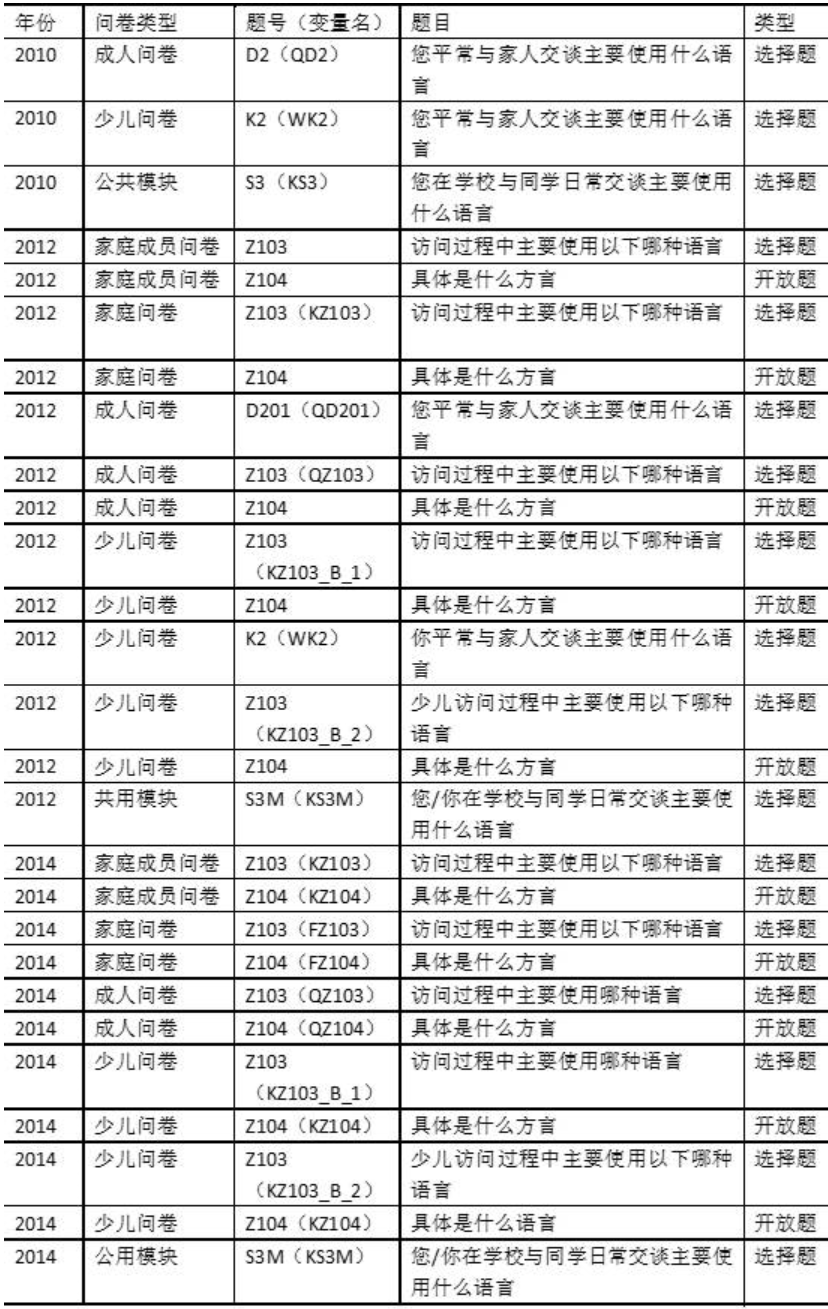
方言编码题目及变量名
编码依据
CFPS方言编码的主要依据是《中国语言地图集》(The Language Atlas of China,以下简称《地图集》)。《地图集》在全面的语言学调查的基础上,按古入声字、古浊声母字的演变规律对汉语方言进行分类,相比其他分类方法更为科学,已成为方言学界实际上的学科标准。《地图集》提供了中国境内汉语方言和少数民族语言的地区分布,汉语方言的分布情况, 和少数民族语言的分布情况。
编码构成
编码由六位数字构成,分别是语系1位、语族1位、大区 (Supergroup or Group)1位、区片(Group or Subgroup)1位、片(Subgroup)2位。
由于这里的编码主要考虑到汉族的语言分布,因此六位编码的前两位总是11(汉藏语系中的汉语语族)。
剩余的四位编码中:
第一位代表大区或者区,具体可以分为十个大类:
(1)官话大区
(2)晋语区
(3)吴语区
(4)赣语区
(5)湘语区
(6)闽语大区
(7)粤语区
(8)客家话区
(9)徽语区
(10)其他话区
第二位代表区或者片(比如,东北官话,或者晋语区中的并州片);第三位和第四位代表官话区中的片(比如东北官话中的吉沈片)。
虽然《地图集》对官话、非官话方言区的片进行了细致的划分, 我们仅对官话大区的语言片进行了编码,而非官话区的语言片则并没有进行编码。 因此,语言编码的后两位数仅在官话区中适用,对于非官话区而言,其方言编码的后两位总是 00。
此外,还有两种特殊情况需要注意。
第一种是“一县多码”,也即有的县包含了多于一种方言。在此情况下, Lavely( 2012) 将其使用的方言在数据中进行列举(至多五种),并标出该地区的“主要方言”。
“主要方言”的确定方法如下:当该区县在地图上被某种方言覆盖时,则确定其为主要方言;当该区县在地图上被多于一种方言覆盖时,该县城的方言则被指定为主要方言(在数据集中,主要方言的位置在第一个语言列中;第二列到第四列的方言没有排序)。
第二种情况是信息缺失,也即对于不被《地图集》覆盖的区县, 对应的方言编码则被留空。
编码原则
编码时,编码员通过被访者填写的文字信息,并结合其所在区县,按照《中国语言地图集》进行编码。整个过程遵循以下基本原则:
1、受访者的回答为“本地话”,按照其所在区县的方言类型编码;
2、受访者回答出的方言类型与其所在区域的方言不符,以受访者回答为准;
3、非单一方言及少数民族语言,统一编码为 99(代表无法编码);
4、受访者的回答为“家乡话”,参照其出生地、 3 岁时户口所在地信息编码。
编码流程
我们采用了双向独立验证并判定( Two-way Independent Verification with Adjudication)的方式进行编码。
第一轮编码由三个编码员分别单独对每一个受访者所填写的方言信息进行编码。
若结果一致,则保留;若不一致,则由另一位经验较为丰富的编码员结合 CFPS 数据中的其他信息,重新确定所属编码类别编码。
温馨提示:方言编码属于CFPS限制数据,如果需要获取CFPS关于方言的数据,点击此处。
请您关注CFPS公众号,阅读更多CFPS小课堂:ISSS_CFPS
上一篇: CFPS小课堂 | 城里人vs.农村人,城乡界定谁说了算?
下一篇: 下面没有链接了